[케라스 창시자에게 배우는 딥러닝] 신경망의 수학적 구성 요소03
신경망의 엔진: 그래디언트 기반 최적화
output=relu(dot(W,input)+b)이 식에서 W와 b는 layer의 속성처럼 볼 수 있다. W는 weight, 가중치, 훈련되는 파라미터 trainable parameter라고 부르며, b는 편향 bias라고 부른다.
초기에는 가중치 행렬이 작은 난수로 채워져 있으나 이후 피드백 신호에 따라 가중치가 조정되어 학습을 하게 된다. 학습, 즉 훈련 train은 아래 단계 안에서 반복된다.
- 훈련 샘플 x와 이에 상응하는 타깃 y의 배치 추출
- x를 사용해 네트워크를 실행하고 예측 y_pred를 구함 (정방향 패스 forward pass일 떄)
- y_pred와 y의 차이를 측정해 이 배치에 대한 네트워크의 손실 계산
- 배치에 대한 손실이 조금 감소되도록 네트워크의 모든 가중치 업데이트
정리하자면
1번 단계는 입출력
2번, 3번 단계는 tensor operation을 사용
4번 단계는 말 그대로 loss를 최소화하도록 네트워크의 가중치를 업데이트
가중치를 어떻게 업데이트할 수 있을까? 어떤 방향으로?
네트워크 가중치 행렬의 원소를 고정하고 관심 있는 하나만 값을 바꿔보는 방법이 있다. 하지만 이 방법은 모든 가중치 행렬의 원소마다 비용이 큰 정방향 패스를 계산해야 하므로 굉장히 비효율적이다.
신경망에 사용된 모든 연산이 미분 가능하다는 장점을 사용해 네트워크 가중치에 대한 손실의 그래디언트를 계산를 계산하는 것이 더 좋은 방법이다. 그래디언트의 반대 방향으로 가중치를 이동하면 손실이 감소된다.
f의 변화율 derivative를 기울기라고 한다.
텐서 연산의 변화율은 그래디언트라고 한다.
입력 벡터x, 행렬w, 타깃y와 손실함수loss가 있다. w를 사용하면 예측y_pred를 계산하고, 손실을 계산할 수도 있다.
y_pred=dot(W,x)
loss_value=loss(y_pred,y)입력 데이터x와 y가 고정이라면 위 함수는 w를 loss값에 매핑하는 함수로 볼 수 있다.
loss_value=f(W)
포인트 W0에서 f의 변화율은 gradient(f)(W0)이다. 이 텐서 gradient(f)(W0)[i,j] 는 (W0)[i,j]를 변경했을 떄 loss_value가 바뀌는 방향과 크기를 나타낸다. 즉 gradient(f)(W0)가 W0에서 함수 f(W)=loss_value의 그래디언트인 것이다.
따라서 그래디언트의 반대 방향으로 W를 움직이면 f(W)의 값을 줄일 수 있다. 하지만 gradient(f)(W0)는 W0에 아주 가까운 값일 때의 기울기를 근사한 것이므로 W0의 근처에 있기 위해 스케일링 비율인 step이 필요하다.
확률적 경사 하강법
신경망에서 손실 함수의 값을 가장 작게 만드는 해결법은 식 gradient(f)(W)=0 을 푸는 것이다. 이 식은 N개의 변수로 이루어진 다항식이며 N은 네트워크의 가중치의 개수이다. 다음과 같은 알고리즘을 사용할 수 있다.
[ 미니 배치 확률적 경사 하강법 mini-batch stochastic gradient descent ]
- 훈련 샘플 배치 x와 이에 상응하는 타깃 y를 추출한다
- x로 네트워크를 실행하고 예측 y_pred를 구한다
- 이 배치에서 y와 y_pred의 차이를 계산해 네트워크의 손실을 계산한다
- 네트워크의 파라미터에 대한 손실 함수의 그래디언트를 계산한다. (역방향 패스 backward pass)
- 그래디언트의 반대 방향으로 파라미터를 조금 이동시킨다.
여기서 확률적 stochastic이란 각 배치 데이터가 무작위로 선택된다는 의미이다.
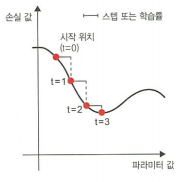
step이 너무 작으면 곡선을 따라갈 때 너무 많은 반복이 필요하고 지역 최소값 local minimum에 갇힐 확률이 높다. 하지만 step이 너무 크면 손실 함수 곡선에서 완전히 임의의 위치로 이동시킬 수 있다.
미니 배치 SGD 알고리즘과는 다르게 반복마다 하나의 샘플과 하나의 타깃을 뽑는 SGD 방법도 존재한다.
사용 가능한 모든 데이터를 사용해 반복하는 배치 SGD 방법도 존재한다. 더 정확하게 업데이트할 수 있지만 그만큼 더 많은 cost가 든다. 이 두가지 알고리즘의 절충안인 미니 배치를 적절한 크기로 사용하는 것이 가장 효율적이라고 할 수 있다.
업데이트할 다음 가중치를 계산할 때 현재의 그래디언트 값만 보지 않고 이전 업데이트된 가중치를 확인하고 여러 다른 방식으로 고려하는 SGD 변종이 있다.
모멘텀을 사용한 SGD, Adagra, RMSProp 등이 있다. 이들은 모두 최적화 방법 optimization method 또는 옵티마이저 optimizer라고 한다. 여기서 모멘텀은 SGD의 문제였던 수렴 속도와 지역 최솟값을 해결해주는 것을 말한다.

역전파 알고리즘
Summary
- 학습: 훈련 데이터 샘플과 그에 상응하는 타깃이 주어졌을 때 손실함수를 최소화하는 모델 파라미터의 조합을 찾는 것
- 데이터 샘플과 타깃의 배치를 랜덤하게 뽑고 이 배치에서 손실에 대한 파라미터의 그래디언트를 계산함으로써 학습 진행
- 네트워크의 파라미터는 그래디언트의 반대 방향으로 조금씩, 그렇지만 학습률에 의해 정의된 만큼만 움직임
- 전체학습 과정은 신경망이 미분 가능한 텐서 연산으로 연결되어 있기 때문에 가능. 현재 파라미터와 배치 데이터를 그래디언트 값에 매핑해주는 그래디언트 함수를 구성하기 위해 미분의 연쇄 법칙 사용
- 손실과 옵티마이저는 네트워크에 데이터를 주입하기 전에 정의되어야 함
- 손실은 훈련하는 동안 최소화해야 할 양이므로 해결하려는 문제의 성공을 측정하는 데에 사용
- 옵티마이저는 손실에 대한 그래디언트가 파라미터를 업데이트하는 정확한 방식 정의