[케라스 창시자에게 배우는 딥러닝] 딥러닝이란 무엇인가
출처: 케라스 창시자에게 배우는 딥러닝 - 프랑소와 숄레 저/ 박해선 역
1.1 AI
AI는 머신러닝과 딥러닝을 포괄하는 종합적인 분야
'충분히 많은 규칙을 명시해 지식을 다루면 인공지능을 인간의 수준까지 인공 지능의 성능을 끌어올 수 있지 않을까?'라는 접근 방식을 심볼릭 AI라고 한다.
심볼릭 AI는 잘 정의되어 있는 논리적인 문제를 푸는 데 적합하지만 Image Classification과 Voice recognition 그리고 Language translation와 같은 복잡한 문제를 다루기에는 어렵다. 이러한 심볼릭 AI를 해결하기 위한 방법이 Machine Learning이다.
1.2 Machine Learning
Machine Learning은 규칙과 규칙에 따라 처리될 데이터를 입력해야 결과가 출력되는 심볼릭 AI와는 다르게 데이터와 데이터로부터 기대되는 결과를 입력하면 규칙을 출력한다. 우리는 이 규칙을 새로운 데이터에 적용시켜 새로운 답을 만들 수 있다.

위 그림을 보면 알 수 있듯이 Machine Learning은 우리가 하고자 하는 테스크와 관련된 샘플을 넣으면 데이터를 통해 통계적 구조를 찾고 이 작업을 자동화하기 위한 규칙을 만든다. Machine Learning은 시스템을 "훈련" 시키는 것이다.
Machine Learning은 통계와 아주 비슷해보이지만 분명히 다르다. Machine Learning은 굉장히 많은 양의 복잡한 데이터들을 다루기 때문에 전통적인 통계 분석 방법 (예를 들면 Bayrsian analysis)을 적용시키기 어렵다. 즉 수학적 이론보다 엔지니어링에 더 가깝다고 할 수 있다.
1.3 Learning expressions from data
Machine Learning을 하기 위해서는 필요한 것이 3가지 있다.
- 입력 데이터 포인트
예1: 주어진 문제가 "음성 인식"일 때의 데이터 포인트는 대화가 녹음된 사운드 파일이다.
예2: 주어진 문제가 "이미지 태깅"일 때의 데이터 포인트는 사진이다.
- 기대 출력
예1: 주어진 문제가 "음성 인식"일 때의 기대 출력은 사람이 사운드 파일을 듣고 옮긴 글이다.
예2: 주어진 문제가 "이미지 태깅"일 때의 기대 출력은 태그이다. (강아지, 고양이 등)
- 알고리즘의 성능을 측정하는 방법
알고리즘의 현재 output과 기대 출력 간의 차이를 결정하기 위해 필요하다. 이때 차이를 계산한 측정값은 알고리즘의 작동 방식을 수정하기 위한 시그널로 다시 피드백된다. 이 수정단계를 학습 Learning이라고 한다.
Machine Learning은 알고 있는 입력과 출력의 샘플로부터 학습을 시행해 입력 데이터를 의미있는 출력으로 변환하기 때문에 핵심은 의미있는 데이터로의 변환이다. 즉 데이터를 인코딩하거나 묘사하기 위해 데이터를 바라보는 방법을 활용해 입력 데이터를 기반으로 기대 출력과 유사하게 만드는 것이다. 왜 이런 방법을 사용하는 것일까?
바로 A 표현으로는 해결하기 어려운 문제가 B 표현으로는 쉽게 해결할 수 있기 때문이다. 특정 색과 채도를 다루는 상황에서의 RGB와 HSV의 경우를 떠올려보자.
좌표 변환 예시도 있다.
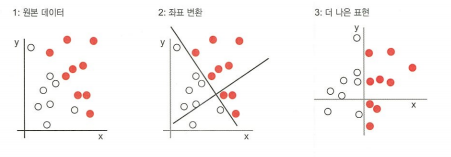
1.4 What is "Deep" in Deep Learning
Deep Learning은 앞서 말했던 Machine Learning의 일부로 연속된 layer에서 의미있는 표현을 배우는 장점을 가지고 데이터로부터 표현을 학습하는 방식이다. 연속된 층으로 표현을 학습하기에 "딥"이라는 표현을 쓴다. 데이터로부터 모델을 만드는 데에 얼마나 많은 layer를 사용했는지가 모델의 깊이를 결정한다.
Deep Learning에서는 기본 layer를 쌓아 신경망 Neural network이라는 모델을 사용해 표현 층을 학습한다. 그렇다면 Deep Learning 알고리즘으로 학습된 표현은 어떻게 나타날까?

final output에 대해 점점 많은 정보를 가지지만 원본 이미지와는 점점 다른 표현으로 숫자 이미지가 변환되는 것을 확인할 수 있다. 정보가 연속된 필터가 심층 신경망을 통과하면서 순도 높게 정제되는 다단계 정보 추출 과정이라고 이해할 수 있다.
1.5 Understand how deep learning works with three figures
layer에서 입력 데이터가 처리되는 상세 내용은 일련의 숫자로 이루어진 layer의 weight에 저장되어 있다. 즉 특정 layer에서 발생한 변환은 그 layer의 weight를 parameter로 가지는 함수로 표현된다는 것이다. 이것은 학습이 주어진 입력을 타깃에 정확한 타깃에 매핑하기 위한 신경망의 모든 layer에 있는 weight를 찾는다는 의미로 이해할 수 있다.
주의해야 하는 점은 파라미터 하나의 값을 바꾸면 다른 모든 파라미터에 영향을 미치기 때문에 대량의 파라미터가 존재할 때 모든 파라미터의 정확한 값을 찾는 것이 어렵다는 것이다.

실제 출력이 기대 출력과 얼마나 차이가 나는지를 알아야 신경망의 출력을 제어할 수 있다. 이는 신경망의 손실 함수 Loss Function 또는 목적 함수 Objective Function가 수행한다.
신경망이 하나의 샘플에 대해 얼마나 잘 예상했는지 측정하기 위해서 손실 함수가 예측과 실제 타깃의 차이를 점수로 계산하고, 이 점수를 피드백 신호로 사용해 현재의 샘플의 손실 함수가 감소되는 방향으로 weight를 수정하도록 하는 것이 딥러닝의 기본 방식이다. 이 과정은 역전파 (Back propagation)과 알고리즘을 구현한 옵티마이저 (Optimizer)가 수행한다.
초기 weight는 랜덤값으로 할당되어 랜덤한 변환을 연속적으로 수행하게 된다. 랜덤한 값이므로 당연히 손실 점수가 높을 것이다. 하지만 네트워크가 모든 샘플을 처리하면 weight가 점차 수정되어 손실 점수도 감소한다. 이 과정을 훈련 반복이라고 하고, 훈련 반복을 충분히 많이 시행하면 손실 함수를 최소화하는 weight 를 얻을 수 있다.